
I am a member of technical staff at OpenAI. I did my PhD at UC Berkeley EECS as a member of Berkeley AI Research, where I was fortunate to be advised by Alexei A. Efros and funded by the PD Soros Fellowship. My main interests are in scalable objectives and architectures for self-supervised and unsupervised learning.
Previously, I've spent time as an intern at DeepMind in London and a student researcher at Google Brain.
Before grad school, I was a Research Engineer at
Facebook AI Research in New York
and studied Computer Science at
Princeton (B.S. 2015).
Teaching
CS 189/289: Introduction to Machine Learning (Spr 2022, Grad TA)
CS 280: Graduate Computer Vision (Spr 2019, Lead TA)
CS 280: Graduate Computer Vision (Spr 2019, Lead TA)
Selected Work (scholar page)

Scalable Adaptive Computation for Iterative Generation.
ArXiv, In Submission.
A Jabri , D Fleet, T Chen.
Universal neural architecture that can adaptively allocate capacity and computation for iterative generation of high-dimensional data. State-of-the-art image and video generation with pure attention-based architecture.
[ paper ] [ project page (soon>) ] [ code (soon) ]
ArXiv, In Submission.
Universal neural architecture that can adaptively allocate capacity and computation for iterative generation of high-dimensional data. State-of-the-art image and video generation with pure attention-based architecture.
[ paper ] [ project page (soon>) ] [ code (soon) ]
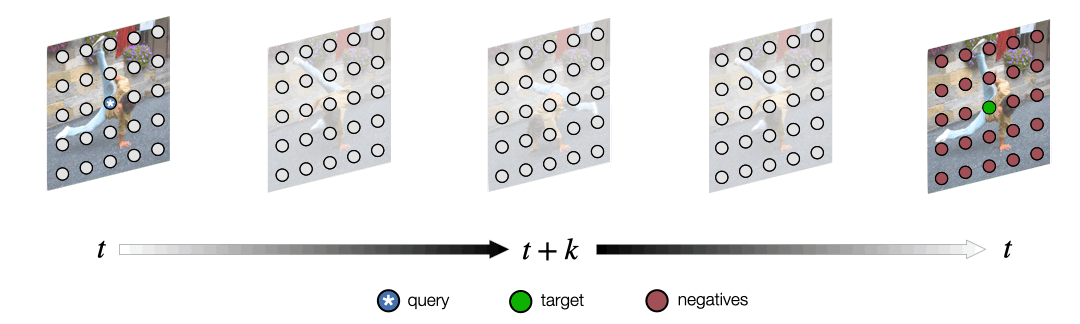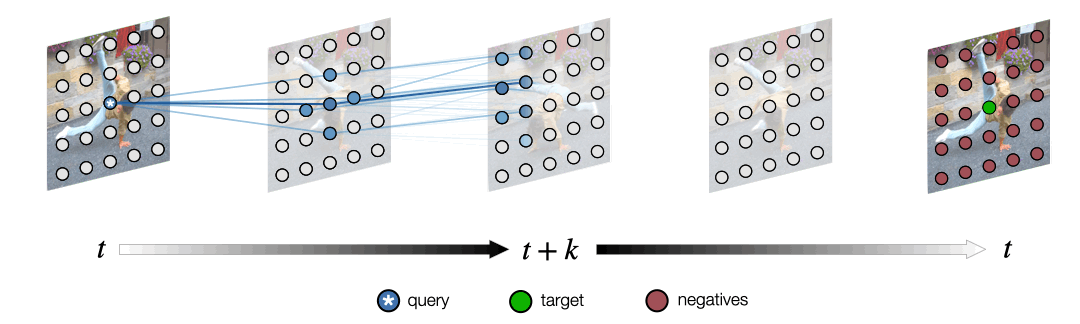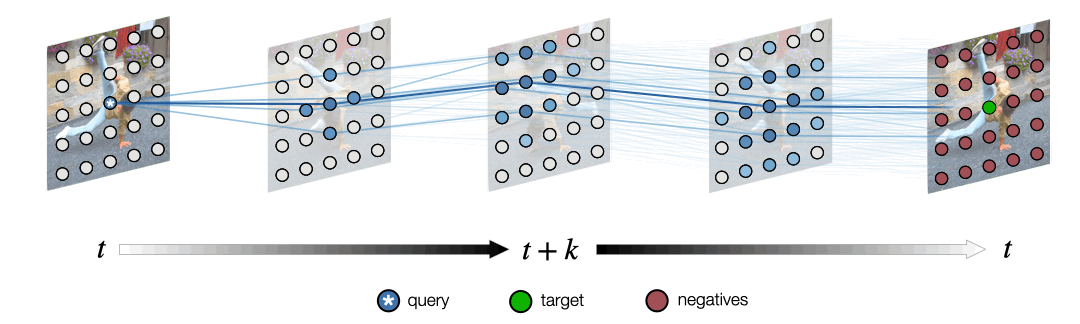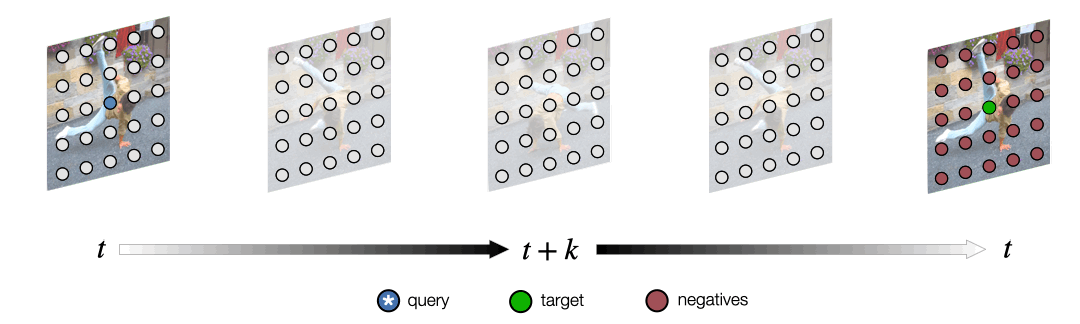
Space-Time Correspondence as a Contrastive Random Walk.
NeurIPS 2020, Oral Presentation.
A Jabri , A Owens, A Efros.
Dense representation learning from unlabeled video, by learning to walk on a space-time graph.
[ paper ] [ project page ] [ code ]
NeurIPS 2020, Oral Presentation.
Dense representation learning from unlabeled video, by learning to walk on a space-time graph.
[ paper ] [ project page ] [ code ]
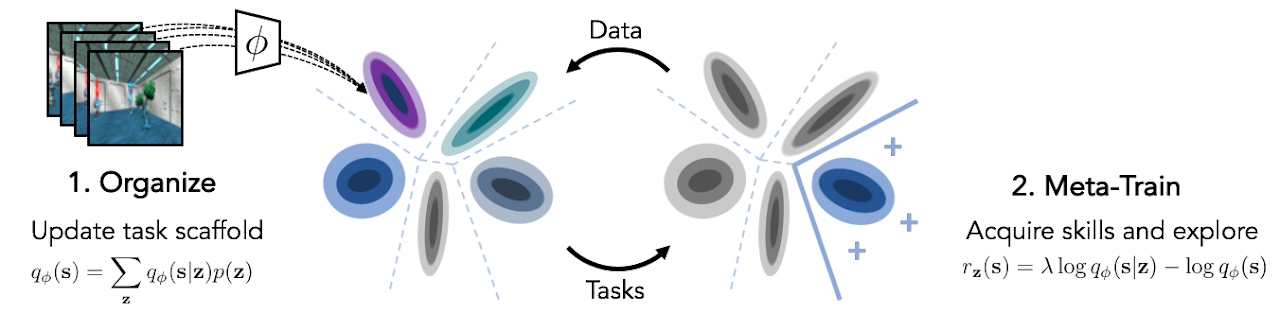
Unsupervised Curricula for Visual Meta-Reinforcement Learning.
NeurIPS 2019, Spotlight Presentation.
A Jabri , K Hsu, B Eysenbach, A Gupta, S Levine, C Finn.
Unsupervised discovery and meta-learning of visuomotor skills, by deep clustering your own trajectories.
[ paper ][ project page ]
NeurIPS 2019, Spotlight Presentation.
Unsupervised discovery and meta-learning of visuomotor skills, by deep clustering your own trajectories.
[ paper ][ project page ]
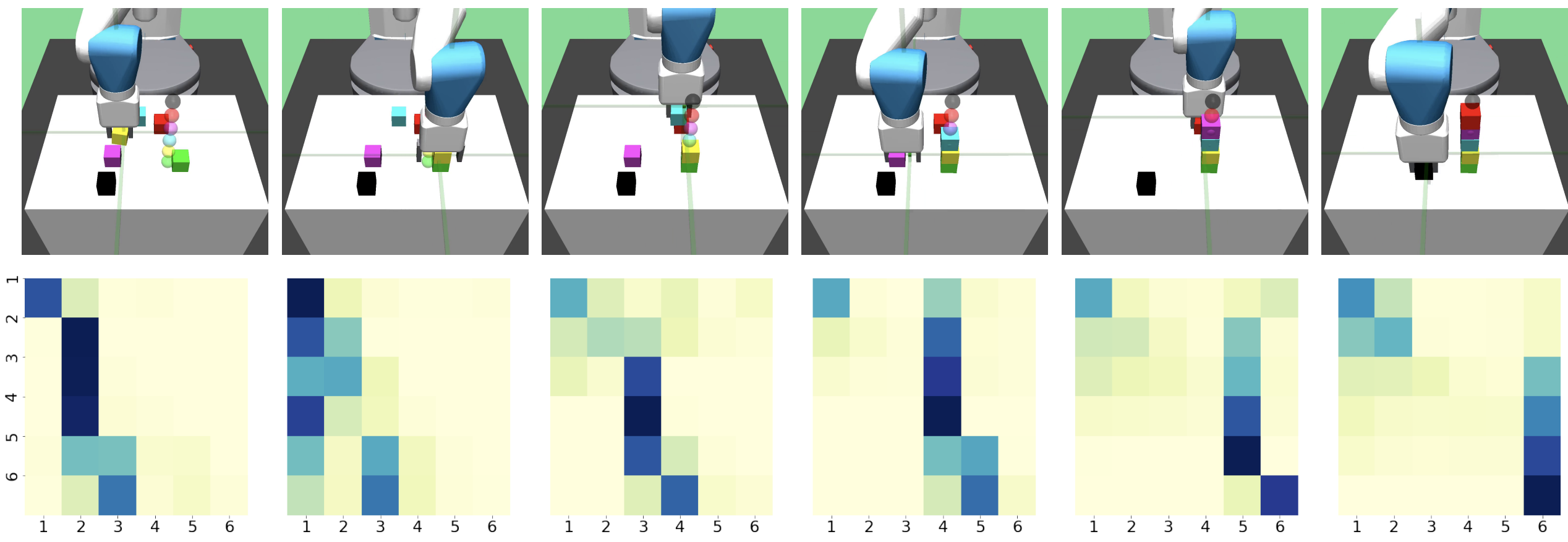
Towards Practical Multi-Object Manipulation using Relational Reinforcement Learning.
ICRA 2020.
R Li,A Jabri , T Darrell, P Agrawal.
Training a graph neural net policy with a simple curriculum leads to task decomposition that generalizes to new configurations.
[ paper ][ project page ][ code ]
ICRA 2020.
R Li,
Training a graph neural net policy with a simple curriculum leads to task decomposition that generalizes to new configurations.
[ paper ][ project page ][ code ]
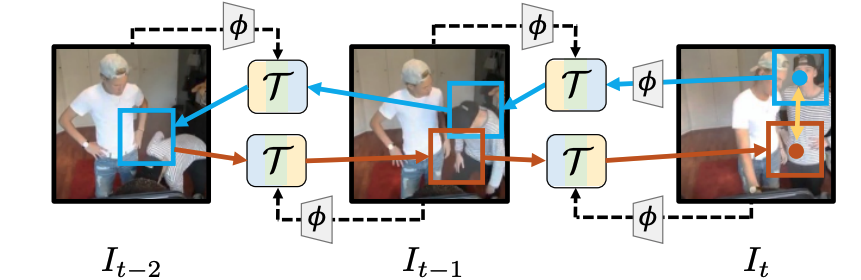
Learning Correspondence from the Cycle-Consistency of Time.
CVPR 2019, Oral Presentation.
X Wang*,A Jabri *, A Efros.
Learn a generic representation for visual correspondence from unlabeled video, using cycle consistency in time.
[ paper ][ project page ][ code ]
CVPR 2019, Oral Presentation.
X Wang*,
Learn a generic representation for visual correspondence from unlabeled video, using cycle consistency in time.
[ paper ][ project page ][ code ]
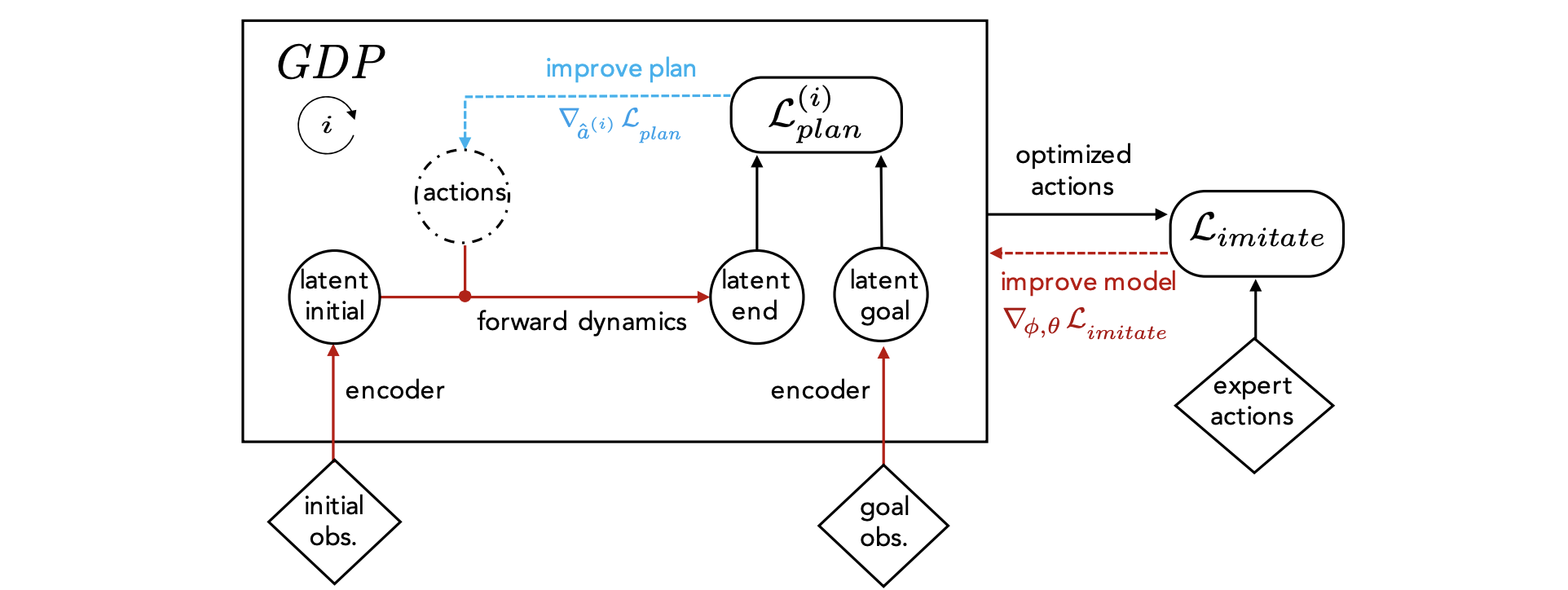
Universal Planning Networks.
ICML 2018.
A Srinivas,A Jabri , P Abbeel, S Levine, C Finn.
Learn a visual representation that captures task semantics by differentiating through model-based planning.
[ paper ] [ project page ] [ code ]
ICML 2018.
A Srinivas,
Learn a visual representation that captures task semantics by differentiating through model-based planning.
[ paper ] [ project page ] [ code ]

CommAI: Evaluating the first steps towards a useful general AI.
ICLR 2017 Workshop
M Baroni, A Joulin,A Jabri , G Kruszewski, A Lazaridou, K Simonic, T Mikolov.
A short paper on the nature of tasks we are studying in the CommAI project.
ICLR 2017 Workshop
M Baroni, A Joulin,
A short paper on the nature of tasks we are studying in the CommAI project.
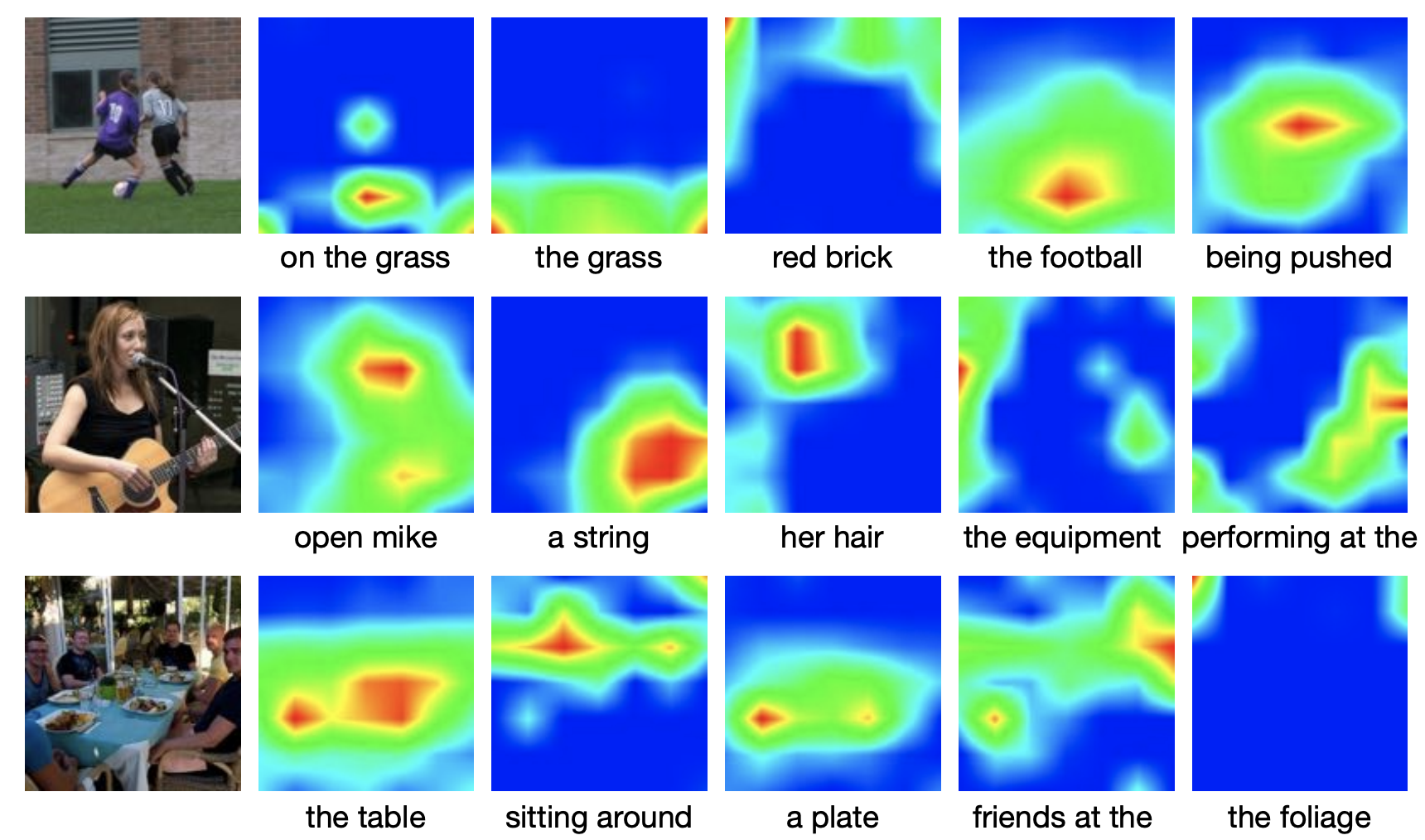
Learning Visual N-Grams from Web Data.
ICCV 2017.
A Li,A Jabri , A Joulin, L van der Maaten.
A smoothed n-gram loss for learning visual representations from compositional phrases, at scale.
[ paper ]
ICCV 2017.
A Li,
A smoothed n-gram loss for learning visual representations from compositional phrases, at scale.
[ paper ]
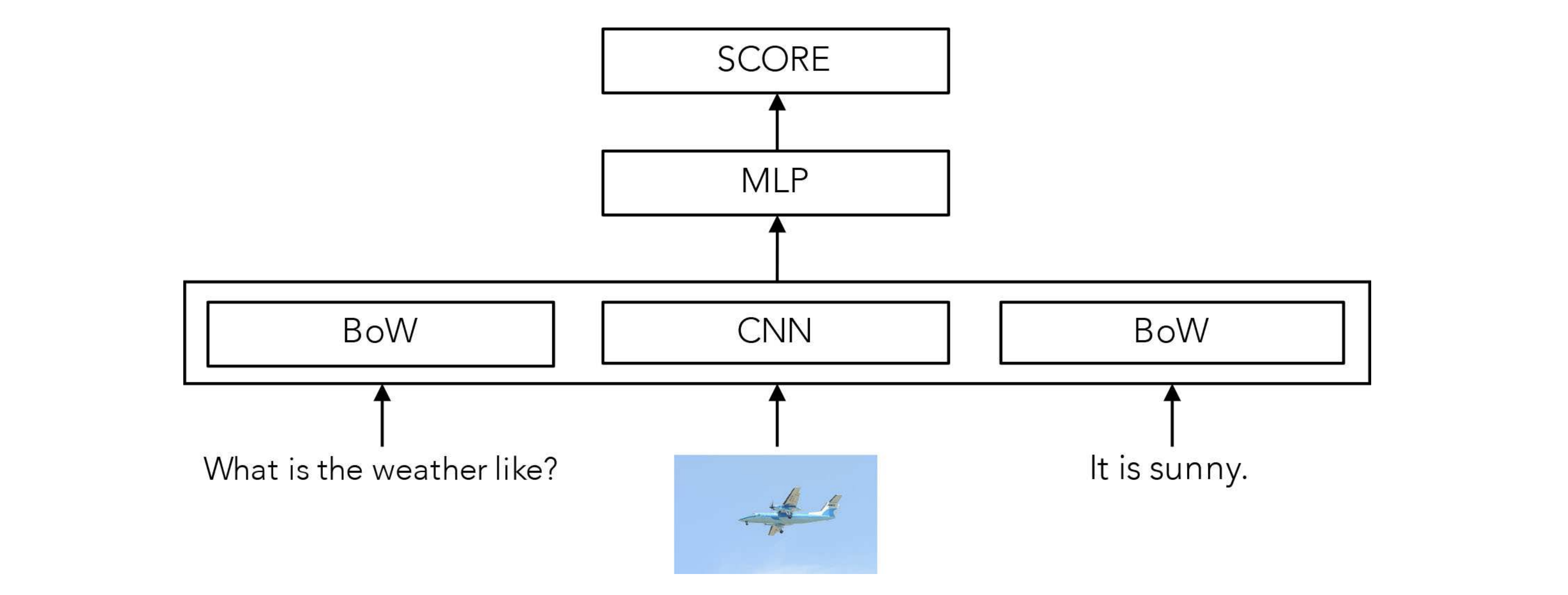
Revisiting Visual Question Answering Baselines.
ECCV 2016.
A Jabri , A Joulin, L van der Maaten.
SOTA VQA models may not be learning what we think they are... #datasetbias
[ paper ]
ECCV 2016.
SOTA VQA models may not be learning what we think they are... #datasetbias
[ paper ]

Learning Visual Features from Large Weakly Supervised Data.
ECCV 2016.
A Joulin, L van der Maaten,A Jabri , N Vasilache.
Learn strong visual features from tons of hashtag data, with interesting byproducts like translation by visual grounding.
[ paper ]
ECCV 2016.
A Joulin, L van der Maaten,
Learn strong visual features from tons of hashtag data, with interesting byproducts like translation by visual grounding.
[ paper ]
ajabri at gmail